
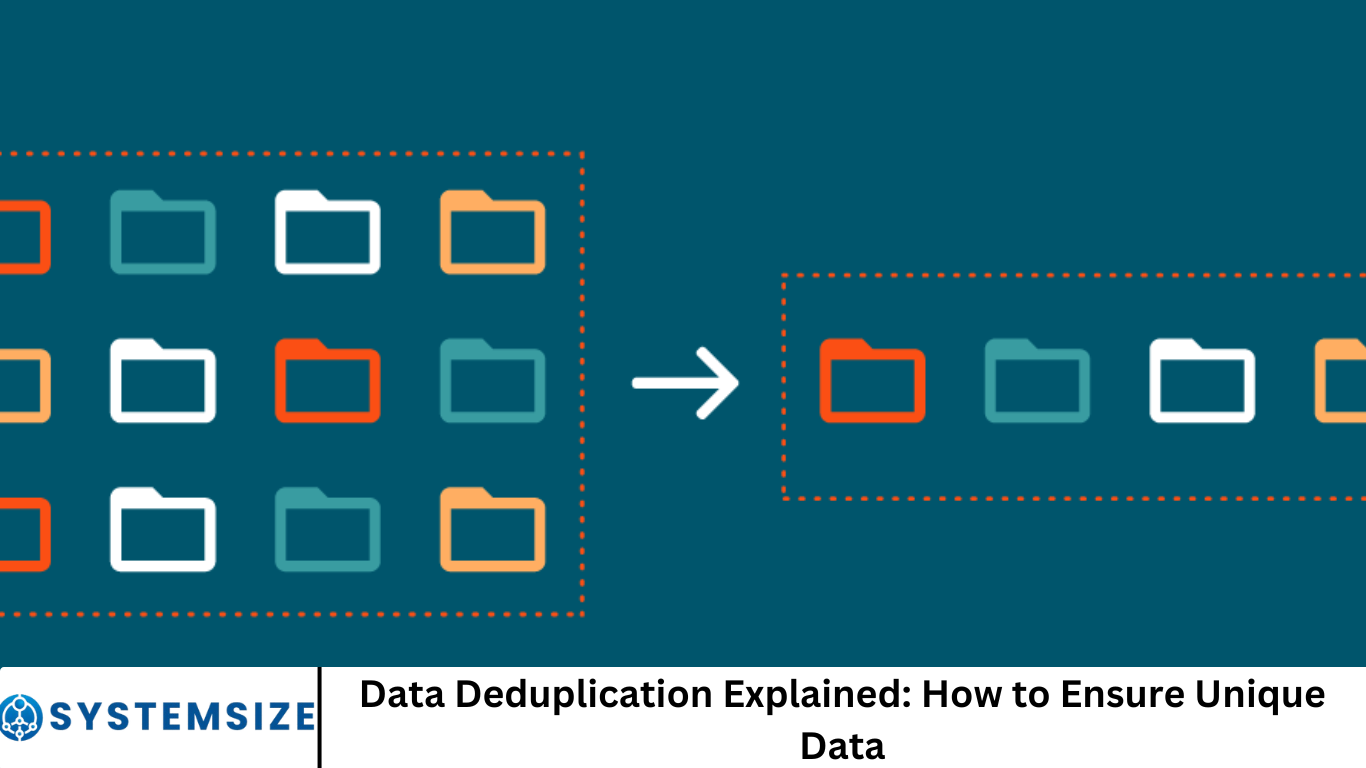
In the digital age, data has become the cornerstone of every successful business. Whether it fuels your marketing campaigns, informs strategic decisions, or powers everyday operations, high-quality data is critical. Yet, one common issue that quietly erodes data integrity is duplication.
Duplicate data entries can lead to inefficiencies, increased costs, and poor customer experiences. That’s where data deduplication comes into play.
This article explores what data deduplication is, why it matters, how it works, and how you can implement effective deduplication strategies to ensure data uniqueness and integrity in your organization.
More Read: Eliminating Duplicate Files: Effective Strategies and Tools
What is Data Deduplication?
Data deduplication is a data compression technique that eliminates redundant copies of data to reduce storage requirements and improve data quality. This process identifies duplicate data blocks and stores only one unique instance, replacing additional copies with a reference to the original.
Deduplication is not just about saving space; it’s about maintaining clean, accurate, and reliable datasets that drive better business outcomes.
Types of Data Deduplication
- File-Level Deduplication (Single Instance Storage):
- Detects duplicate files and stores only one copy.
- Commonly used in email systems or file storage solutions.
- Block-Level Deduplication:
- Identifies duplicate blocks of data within or across files.
- Offers greater storage efficiency than file-level deduplication.
- Byte-Level Deduplication:
- Analyzes data byte by byte to find redundancies.
- Most granular and efficient but computationally intensive.
Why is Data Deduplication Important?
1. Reduces Storage Costs
By eliminating redundant data, organizations can dramatically cut down on storage requirements. This is particularly crucial for businesses that manage large volumes of data, such as media companies, financial institutions, and healthcare providers.
2. Improves Data Accuracy
Duplicate records can lead to inconsistencies, reporting errors, and flawed analytics. Deduplication ensures a single source of truth for every data point.
3. Enhances Operational Efficiency
Managing duplicate data wastes time and resources. Employees may contact the same customer multiple times, run inaccurate reports, or struggle to find correct information.
4. Boosts Customer Experience
Data deduplication ensures that your CRM and marketing automation tools only contact each customer once, providing a personalized and seamless experience.
5. Strengthens Data Compliance
Regulatory frameworks like GDPR and HIPAA demand accurate, secure, and minimal data storage. Deduplication helps organizations stay compliant by removing unnecessary copies of personal information.
Common Causes of Duplicate Data
Understanding the root causes of duplicate data is the first step toward effective deduplication.
- Manual Data Entry: Human error is one of the leading causes of duplication. Typos, formatting inconsistencies, and accidental re-entry can all lead to multiple versions of the same record.
- Data Integration from Multiple Sources: Merging data from different platforms (e.g., CRM, ERP, marketing tools) often results in duplicated entries.
- Lack of Standardization: Without consistent data formats or naming conventions, systems may not recognize similar entries as duplicates.
- Import Errors: Importing data from spreadsheets or third-party tools can introduce duplicate records if deduplication rules aren’t enforced.
How Does Data Deduplication Work?
1. Data Scanning and Identification
The deduplication process starts by scanning datasets to identify potential duplicates. Algorithms compare records based on predefined rules (e.g., exact match, fuzzy match, checksum).
2. Data Matching Techniques
- Exact Matching: Finds records that are identical in every field.
- Fuzzy Matching: Detects similar records using algorithms like Levenshtein distance or Soundex, which can identify typos or misspellings.
3. Duplicate Resolution
Once duplicates are identified, the system either merges them into a single record or removes them, depending on the organization’s data governance policy.
4. Reference and Compression
In storage-level deduplication, duplicate blocks are replaced with pointers to the original, freeing up space without losing data access.
Tools and Technologies for Data Deduplication
Numerous tools exist to facilitate data deduplication, each offering unique features and integrations:
1. Data Quality Platforms
- Talend Data Quality
- Informatica Data Quality
- OpenRefine
2. CRM and Marketing Automation Tools
- Salesforce Duplicate Management
- HubSpot Contact Deduplication
- Zoho CRM Deduplication
3. Backup and Storage Solutions
- Veeam Backup & Replication
- Dell EMC Data Domain
- Veritas NetBackup
Best Practices for Ensuring Unique Data
1. Standardize Data Entry
Establish clear guidelines for how data should be entered into your systems. Use dropdowns, validation rules, and formatting tools to reduce variation.
2. Implement Real-Time Deduplication
Use automation tools that identify and eliminate duplicates at the point of entry.
3. Regularly Audit Your Data
Schedule periodic reviews of your datasets to catch and resolve duplicates before they cause issues.
4. Train Your Team
Educate staff on the importance of data accuracy and provide training on how to prevent duplicate entries.
5. Leverage AI and Machine Learning
Advanced deduplication systems use machine learning to continuously improve their accuracy in identifying duplicates.
Challenges in Data Deduplication
1. False Positives/Negatives
Poorly configured matching algorithms can either merge non-duplicates or miss actual duplicates.
2. Data Privacy Concerns
In sensitive industries, deduplication processes must ensure that data integrity and confidentiality are maintained.
3. System Performance
Deduplication processes can be resource-intensive, particularly with large datasets.
4. Change Management
Integrating deduplication into existing workflows may require cultural and operational adjustments.
Case Study: How a Retail Company Improved CRM Accuracy with Deduplication
A mid-sized retail company was facing challenges with its CRM system, including multiple entries for the same customer, inconsistent communication, and inaccurate reporting.
Solution: The company implemented a deduplication tool integrated with their CRM. It identified duplicates using fuzzy logic and allowed manual review for uncertain matches.
Results:
- Reduced duplicate entries by 85%
- Improved email campaign click-through rates by 20%
- Streamlined customer support interactions
Future of Data Deduplication
With the rise of big data, cloud storage, and AI-driven analytics, deduplication technologies are evolving rapidly.
- Cloud-Based Deduplication: More organizations are adopting deduplication as a service (DaaS) to manage cloud storage efficiently.
- AI-Powered Deduplication: Machine learning algorithms enhance accuracy in identifying duplicates with minimal human intervention.
- Real-Time Deduplication: Future systems will offer more robust real-time capabilities integrated into all data entry points.
Frequently Asked Question
What is data deduplication, and why is it important?
Data deduplication is a technique used to identify and eliminate redundant copies of data. It’s essential because it improves data accuracy, reduces storage costs, and enhances overall data quality, which supports better business decisions and compliance.
How does data deduplication differ from data cleansing?
While data deduplication focuses on removing duplicate entries, data cleansing is a broader process that includes correcting errors, standardizing formats, and removing irrelevant or outdated information. Deduplication is often a part of the larger data cleansing effort.
What are the main types of data deduplication?
There are three primary types:
- File-level deduplication (removes identical files),
- Block-level deduplication (removes duplicate blocks within files),
- Byte-level deduplication (removes duplicate bytes, offering the most granularity).
How can I detect duplicate data in my systems?
You can detect duplicates using exact matching (identical fields), fuzzy matching (similar but not identical records), or specialized software tools that scan and analyze your database for redundancy patterns.
What tools can help with data deduplication?
Popular tools include:
- Talend Data Quality
- Informatica
- Salesforce Duplicate Management
- HubSpot Deduplication
- Veeam Backup & Replication
These tools offer varying capabilities such as real-time deduplication, fuzzy matching, and AI-powered recommendations.
How often should deduplication be performed?
Deduplication should be a continuous or regularly scheduled process. Many organizations implement real-time deduplication at the point of data entry and conduct audits monthly or quarterly depending on data volume and criticality.
Can deduplication cause data loss?
If not implemented carefully, deduplication algorithms might incorrectly merge distinct records or delete important information. That’s why it’s critical to use trusted tools, configure rules accurately, and perform manual reviews for uncertain matches.
Conclusion
Data deduplication is more than a technical process—it’s a vital strategy for maintaining the health and effectiveness of your data ecosystem. By implementing the right tools, practices, and technologies, businesses can ensure their data is clean, unique, and ready to drive intelligent decisions. Whether you’re managing a customer database, optimizing storage systems, or fine-tuning your marketing campaigns, investing in data deduplication will pay off in better performance, lower costs, and stronger outcomes.
