
Systematic reviews are a cornerstone of evidence-based research, providing comprehensive syntheses of existing studies to inform decisions in healthcare, policy, and other fields. However, a significant and time-consuming hurdle in this process is the removal of duplicate records—a tedious task that can delay review timelines and increase the risk of human error.
Enter Deduplicator, an automated tool designed to streamline and optimize the process of duplicate record removal in systematic reviews. By leveraging advanced algorithms and machine learning, Deduplicator reduces manual workload, enhances accuracy, and accelerates the overall review process.
More Read: Detecting and Managing Duplicate Files: An Analytical Approach
Why Duplicate Records Are a Problem in Systematic Reviews
1. What Are Duplicate Records?
Duplicate records are instances of the same study or publication appearing multiple times in a database or set of search results. They arise when data is retrieved from multiple sources like PubMed, Scopus, Web of Science, and Embase, which often index the same journals.
2. Consequences of Not Removing Duplicates
- Inflated study counts: Leads to misinterpretation of literature volume.
- Skewed data analysis: Risk of including the same results more than once.
- Time-wasting during screening: Reviewers repeatedly evaluate the same studies.
- Reduced credibility of findings: Undermines the systematic review’s methodological rigor.
3. Manual Deduplication: Time-Consuming and Error-Prone
Traditionally, deduplication is carried out using reference management software like EndNote, Zotero, or Mendeley. These tools rely heavily on exact matches of key fields such as title, author, or DOI. However, inconsistencies in metadata formatting often cause many duplicates to go undetected—or mistakenly flagged as unique.
Introducing Deduplicator: The Game-Changer for Systematic Reviews
What Is Deduplicator?
Deduplicator is an AI-powered software tool specifically designed to automate the detection and removal of duplicate records in systematic reviews. It uses fuzzy matching, natural language processing (NLP), and probabilistic modeling to go beyond exact matching, enabling it to identify duplicates even with metadata discrepancies.
Key Features of Deduplicator
- Advanced Fuzzy Matching Algorithms: Identifies duplicates with variations in titles, author names, or journal formatting.
- Cross-Database Compatibility: Works with multiple export formats (RIS, BibTeX, CSV, EndNote XML).
- Bulk Processing: Processes thousands of records in minutes.
- User-friendly Interface: Intuitive design for both novice and expert users.
- Transparent Reporting: Generates logs and summary reports for audit trails.
- Customizable Matching Rules: Tailor sensitivity levels for various research contexts.
How Deduplicator Works: Step-by-Step
Step 1: Data Import
Users upload their bibliographic data files exported from databases. Deduplicator supports major formats, ensuring smooth integration with common research workflows.
Step 2: Preprocessing
The tool cleans and standardizes data by:
- Normalizing text (removing punctuation, converting to lowercase)
- Standardizing date and author formats
- Removing special characters
Step 3: Duplicate Detection
Deduplicator uses a combination of methods:
- Exact Matching: For identical entries
- Fuzzy Logic Matching: Uses Levenshtein distance or similar algorithms to compare slightly different records
- Machine Learning Models: Trained on labeled datasets of duplicates and non-duplicates to improve precision and recall
Step 4: User Review (Optional)
Although automation is powerful, Deduplicator allows researchers to manually review flagged duplicates before deletion for added confidence.
Step 5: Export and Reporting
After deduplication, users can export clean datasets along with logs showing:
- Number of duplicates removed
- Criteria used for matching
- Retained record preferences
Benefits of Using Deduplicator
1. Improves Accuracy and Consistency
Manual deduplication is prone to oversight. Deduplicator’s algorithmic rigor ensures higher detection accuracy across large and diverse datasets.
2. Saves Time and Resources
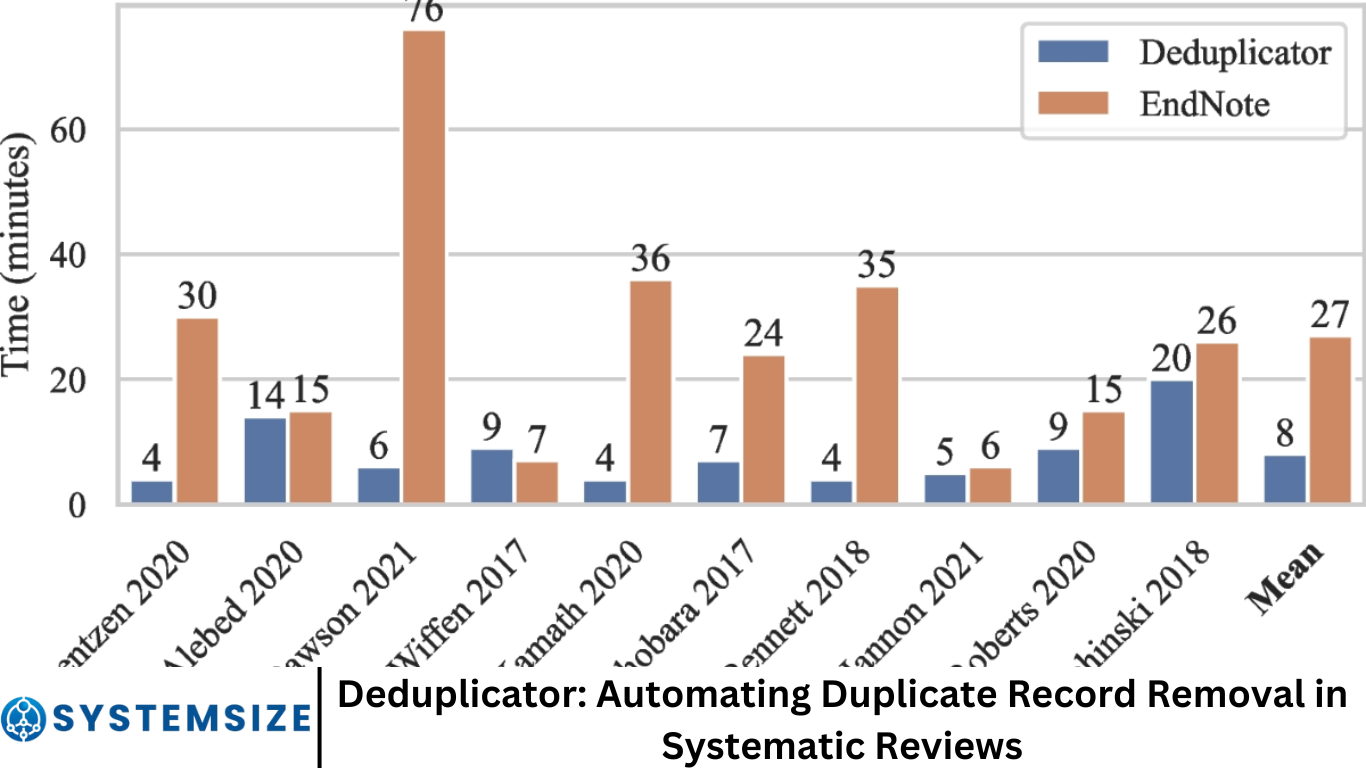
Researchers report time savings of up to 70% during the screening phase, allowing them to focus more on analysis and less on data cleaning.
3. Reduces Reviewer Fatigue
Repeated exposure to duplicate entries can lead to decision fatigue and inconsistent inclusion criteria. Automating this step reduces mental load.
4. Scalable for Large Reviews
Whether dealing with 500 or 50,000 references, Deduplicator handles bulk processing effortlessly, making it ideal for scoping reviews and meta-analyses.
5. Enhances Transparency and Reproducibility
Every step of the deduplication process is logged, enabling peer reviewers or auditors to trace decisions and ensure methodological integrity.
SEO Keywords to Know
If you’re researching Deduplicator or looking to improve systematic review workflows, here are some relevant SEO keywords:
- automated deduplication
- systematic review software
- duplicate record detection tool
- AI in systematic reviews
- reference deduplication
- evidence synthesis tools
- literature screening automation
- duplicate removal software for research
Comparison with Traditional Tools
| Feature | Manual Deduplication (EndNote, Zotero) | Deduplicator |
|---|---|---|
| Speed | Slow (hours to days) | Fast (minutes) |
| Accuracy | Limited (exact match only) | High (fuzzy + ML-based) |
| Learning curve | Moderate | Low |
| Scalability | Limited | High |
| Reporting | Basic | Detailed |
| User Control | Manual decisions | Manual + automated options |
Use Cases and Success Stories
1. Healthcare Meta-Analysis
A group conducting a meta-analysis on COVID-19 treatments reduced their dataset from 22,000 to 11,800 records in under 10 minutes using Deduplicator. Manual methods had previously taken them over 3 days for a similar review.
2. Academic Librarianship
University librarians training students in systematic review methodology now include Deduplicator in their instruction as a critical component of efficient and ethical review practices.
3. Public Policy Reviews
NGOs conducting evidence syntheses on climate change policies used Deduplicator to streamline large multi-database searches, improving accuracy in government reporting.
Tips for Best Use
- Always review borderline duplicates manually if Deduplicator flags them with low confidence.
- Customize matching settings based on your review’s needs—broader for scoping reviews, stricter for Cochrane-standard meta-analyses.
- Use clean metadata from the start. Garbage in = garbage out.
- Integrate Deduplicator into early-stage protocols to reduce wasted screening effort.
Future of Automation in Systematic Reviews
Deduplicator is just one piece of a broader trend: automation in evidence synthesis. From machine learning tools for study classification to AI-assisted data extraction, the systematic review process is being transformed.
Upcoming enhancements to Deduplicator may include:
- Real-time deduplication during database searching
- Integration with screening platforms like Rayyan, Covidence, or EPPI-Reviewer
- Collaborative review features for teams
- Multilingual metadata support
Frequently Asked Question
What is Deduplicator and how does it work?
Deduplicator is an automated tool designed to detect and remove duplicate records in systematic reviews. It works by importing bibliographic data from multiple sources, standardizing metadata, and using fuzzy matching algorithms and machine learning to identify duplicates—even when they are not exact matches. The result is a cleaner dataset, ready for screening and analysis.
What file formats does Deduplicator support?
Deduplicator supports a wide range of reference formats commonly used in systematic reviews, including:
- RIS
- BibTeX
- CSV
- EndNote XML
- PubMed .nbib
This ensures compatibility with popular reference managers and databases like EndNote, Zotero, Mendeley, PubMed, Scopus, and Web of Science.
How accurate is Deduplicator compared to manual methods?
Deduplicator offers significantly higher accuracy than manual or basic reference manager deduplication. By using fuzzy logic and AI, it can detect near-duplicates with minor variations in metadata, which traditional tools often miss. It also allows for manual review of borderline cases to ensure high precision.
Can I customize the duplicate matching rules?
Yes. Deduplicator provides customizable settings for duplicate detection sensitivity. You can adjust thresholds for fuzzy matching, choose preferred fields for comparison (e.g., title, author, year), and set rules for which version of a duplicate to retain (e.g., based on completeness or publication date).
Does Deduplicator integrate with other systematic review tools?
Deduplicator is designed to integrate smoothly with review workflows. While it doesn’t always integrate directly with every screening platform, it produces clean, exportable datasets that are compatible with tools like:
- Covidence
- Rayyan
- EPPI-Reviewer
- RevMan
Future versions are expected to offer direct integrations and API support.
Is Deduplicator suitable for large-scale reviews with tens of thousands of records?
Absolutely. Deduplicator is built to handle large datasets efficiently—processing tens of thousands of references in just minutes. This makes it ideal for large scoping reviews, umbrella reviews, and meta-analyses that involve multi-database searches.
Is Deduplicator free to use?
Deduplicator’s pricing and access model can vary depending on the provider or institution. Some versions may be:
- Freely available as open-source
- Offered as part of academic licensing packages
- Available through subscription or pay-per-use platforms
Always check the official website or product page for the most current access options and pricing details.
Conclusion
Duplicate record removal may seem like a mundane task, but it’s a crucial step in the integrity and efficiency of systematic reviews. With the explosion of published research, manual methods are no longer viable at scale. Deduplicator offers a fast, accurate, and transparent solution that automates this process while maintaining researcher oversight. Its adoption not only saves time but also enhances the credibility and reproducibility of evidence syntheses. For any researcher aiming to produce high-quality systematic reviews, Deduplicator is not just a tool—it’s an essential ally in the pursuit of scientific rigor and efficiency.
